How to build a ML model?

There are four basic steps for building a machine learning model or application. These steps are typically performed by data scientist working closely with the professionals for whom the model is being developed.
Step 1: Identify suitable data set and prepare the training data set
Training data is a data set representative of the data the machine learning model will take to solve the problem it’s designed to solve. In some cases, the training dataset is labelled data (tagged) to call out the features and classification the model will need to identify. Other data is unlabelled, and the model will need to extract those features and assign classification on its own.
In either case, the training data need to be correctly prepared-randomized and check for un-biased or imbalance that could impact the training. It should also be divided into two subsets as training dataset and testing dataset (Training Dataset: Data that are used to train the model, normally 70% of the data set will be allocated to the training process. Testing Dataset: Data that is used for the testing purpose of the model, normally 30% of the dataset will be allocated to the testing purpose). To split data set into two subsets we usually used the `sklearn.model_selection` library.
Step2: Choose an algorithm to run the on the training dataset
The type of the algorithm is based on the type of the model and size of the dataset used to train the model.Common types of machine learning algorithm for use with the labelled data as Regression, Decision Tree, Instance-Based Algorithm, Clustering, Association and the newly invented advance algorithm as Neural Network.
Algorithums can use with labelled data
- Regression algorithms : Linear and logistic regression are examples of regression algorithms used to understand relationships in data. Linear regression is used to predict the value of a dependent variable based on the value of an independent variable. Logistic regression can be used when the dependent variable is binary in nature: 1 : 0. For exsample, a linear regression could be train to predict tomorrow stock value using the previous data.Another type of the regression algorithm is Support Vector Machine Algorithm, is useful when dependent variables are more and difficult to classify.SVM is mostly used for the person recognition , plant leaf recognition with more detailed image details.
- Decision trees: Decision trees use classified data to make recommendations based on a set of decision rules. For example, a decision tree that recommends betting on a particular cricket match win or loss or draw (e.g., player;s experience, age, number of run in last year etc) and apply rules to those factors to recommend an action or decision.
- Instance-based algorithms: A good example of an instance-based algorithm is K-Nearest Neighbor or k-nn. It uses classification to estimate how likely a data point is to be a member of one group or another based on its proximity to other data points.

Algorithums can use with unlabelled data
- Clustering algorithms: Think of clusters as groups. Clustering focuses on identifying groups of similar records and labeling the records according to the group to which they belong. This is done without prior knowledge about the groups and their characteristics. Types of clustering algorithms include the K-means, TwoStep, and Kohonen clustering.
- Neural Network: A neural network is a series of algorithms that endeavors to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates. In this sense, neural networks refer to systems of neurons, either organic or artificial in nature. Neural networks can adapt to changing input; so the network generates the best possible result without needing to redesign the output criteria. The concept of neural networks, which has its roots in artificial intelligence, is swiftly gaining popularity in the development of trading systems.
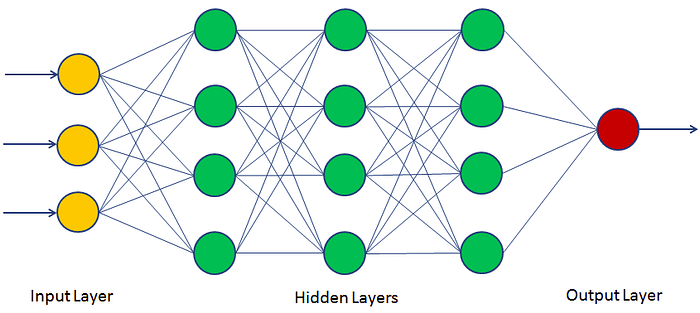
Step 3: Training the algorithm to create the model
Training the algorithm is an iterative process–it involves running variables through the algorithm, comparing the output with the results it should have produced, adjusting weights and biases within the algorithm that might yield a more accurate result, and running the variables again until the algorithm returns the correct result most of the time. The resulting trained, accurate algorithm is the machine learning model — an important distinction to note, because ‘algorithm’ and ‘model’ are incorrectly used interchangeably, even by machine learning mavens.
Step 4: Using the pre-trained model for implementation and improving the model
The final step is to use the model with new data and, in the best case, for it to improve in accuracy and effectiveness over time. Where the new data comes from will depend on the problem being solved. For example, a machine learning model designed to identify spam will ingest email messages, whereas a machine learning model that drives a robot vacuum cleaner will ingest data resulting from real-world interaction with moved furniture or new objects in the room.
Source Code : Diabetic Prediction using Machine Learning
For more Machine Learning Projects : GitHub
Read More : Artificial Intelligence , What is Machine Learning , Deep Learning
